
W ostatnim czasie tematem numer jeden w branżach związanych z internetem i nie tylko, jest ChatGPT, czyli sztuczna inteligencja, która zna odpowiedzi na „wszystkie” pytania. ChatGPT potrafi pisać artykuły, rozwiązywać najbardziej skomplikowane zadania matematyczne, pisać skrypty, a nawet opowiadać alternatywne historie i żarty. Doszło do tego, że niektórzy internauci zwracają się do programu po imieniu: „Hej ChatGPT, mam do ciebie pytanie…”. Wielu komentatorów i znawców tematu już teraz odsyła na emeryturę dziennikarzy, publicystów czy redaktorów. ChatGPT jest niewątpliwie narzędziem niezwykłym, dającym niesamowite możliwości, jeśli potrafi się z niego korzystać. Jest również zagrożeniem.
Wyobraźmy sobie, co wcale nie jest, aż tak abstrakcyjne, że sztuczna inteligencja w najbliższych latach zastąpi popularne wyszukiwarki internetowe. Po co wchodzić na „jakąś” wyszukiwarkę, jeśli odpowiedzi na nurtujące nas pytania pojawiają się sekundę po zapytaniu na czacie. Co to oznacza dla właścicieli stron internetowych przekonujemy się już od jakiegoś czasu, ponieważ wyniki organiczne spychane są co chwilę, a to przez większą ilość reklam, a to przez tzw. wyniki zerowe wyszukiwania czy filmy. Warto natomiast zadać sobie pytanie co zrobi samo Google, które po pierwsze zostanie „zalane” niesamowitą ilością treści ciężką do zweryfikowania pod względem wartości, a po drugie jako wyszukiwarka może stać się archaicznym przeżytkiem jak kasety VHS czy dyskietki.
Google stawia na autora
Może inaczej, Google powinno postawić na autora z kilku powodów. Głównym z nich jest według mnie fakt, że wielu internautów pozyskując informacje, ich rzetelność uzależnia od dorobku naukowego autora, od jego wcześniejszych publikacji, a czasem od wykształcenia kierunkowego. Ludzie szukają autorytetów, tymczasem od AI otrzymują informację obdartą ze źródła pochodzenia. Można trywialnie zapytać czy smaczniejsza będzie jajecznica zaproponowana przez ChatGPT czy kucharza pracującego w restauracji która posiada 3 gwiazdki Michelin. Człowiek vs Chat.
Kiedy autor staje się autorytetem?
W 2014 roku firma Google zarejestrowała patent: „Wiarygodność autora treści internetowych”. Możemy w nim przeczytać między innymi o tym, że autor może być autorytetem w kilku dziedzinach oraz, że o jego reputacji świadczy miedzy innymi liczba linków do jego publikacji. Jest również wzmianka o tym, że reputacja może być obniżona w przypadku powielania tej samej treści i że jest ona niezależna od reputacji wydawcy (https://patents.google.com/patent/US8126882B2/en).

Szerzej tematowi przyjrzał się w 2022 roku, fan rozkładania patentów Google na części pierwsze czyli ś.p. Bill Slawski, który sugerował, że Google już w 2007 roku mogło brać pod uwagę rolę autora opierając się na tzw. Agent Rank – patencie Google, który w latach późniejszych był jeszcze wielokrotnie modyfikowany.
Kolejna próbą wzmocnienia roli autora było oznaczenia autorstwa w niedziałającym już Google+. Ten wątek podejmuje w swoim opracowaniu Koray Tuğberk GÜBÜR który twierdzi, że oprócz Google+ z rankingiem autorów związane są lub były również: Google Answers, Google Talk, Google Knol, Google Sidewiki i Google Groups. Serwisy te według wielu specjalistów wykorzystywane są do budowania tak zwanych „knowledge graph” o których wspominam w dalszej części artykułu.
W międzyczasie twórcy najpopularniejszej wyszukiwarki próbowali przekonać autorów do oznaczania swojej treści poprzez znacznik rel=„author”. Jednak po trzech latach od jego wprowadzenia, w 2014 roku kiedy okazało się, że tylko 30% twórców skorzystało z tej możliwości, tag został usunięty. Prób było dużo więcej. Przykładowo w 2021 roku do dokumentacji na temat uporządkowanych danych Article dodana została nowa zalecana właściwość author.url., która pomaga Google jednoznacznie określić prawidłowego autora artykułu.
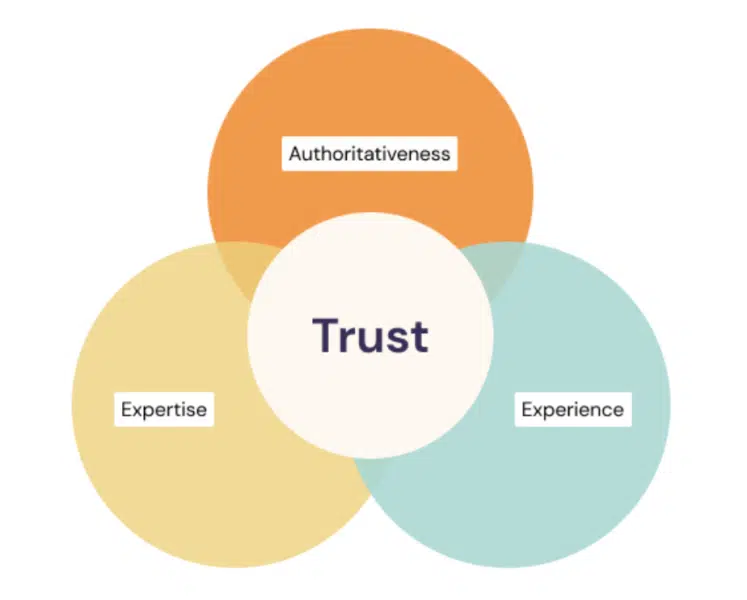
Temat powrócił za sprawą aktualizacji „Search Quality Evaluator Guideline”, czyli dokumentu zawierającego wytyczne dla webmasterów. W 2018 roku Google przeprowadził tak zwany Medical Update – aktualizację algorytmu po której widoczność w wyszukiwarce straciło wiele stron z kategorii YMYL (Your Money Your Life), w większości były to strony, których content można określić jako dotyczący kluczowych aspektów życia użytkowników. Wtedy też na znaczeniu zyskała reguła E-A-T oznaczająca:
- Expertise, czyli eksperckości publikowanych treści,
- Authoritativeness, oznaczającej autorytet w danej dziedzinie,
- Trustworthiness, czyli zaufaniu do danej marki.
Nawiązując do tematu można powiedzieć, że Google przygotował koncepcję identyfikacji marki i podjął próbę zapewniania jakości, poprzez weryfikację m.in. autorów. Co ciekawe pierwszy raz wzmianka o E-A-T pojawiła się w Quality Rater Guidelines w 2014 roku, czyli dokładnie wtedy kiedy został zarejestrowany patent: „Wiarygodność autora treści internetowych”. Historia zatoczyła koło.
Wykorzystanie Entities
Algorytm Hummingbird został wprowadzony w 2013 roku i miał wpływ na około 90% zapytań do Google. To co różniło go od wcześniejszych aktualizacji np. Pingwina i Pandy to fakt, że Hummingbird nie karał stron, a całkowicie zmienił sposób reakcji wyszukiwarki na zapytania. Zaczęto wykorzystywać kontekst oraz intencję zapytania – pojawiło się wyszukiwanie semantyczne. Relacje między podmiotami, ludźmi i tematami nabrały większego znaczenia. Duża rolę w tej układance odegrały tak zwane „knowledge graph”, czyli wykresy wiedzy, które pierwszy raz zobaczyliśmy na około rok przed aktualizacją (tzw. knowledge panel). Połączenie powiązań z bazą danych i relacje między nimi sprawiły, że Google teoretycznie mógł wykorzystać je do oceny autorytetu autora, czyli elementu koncepcji E-A-T.
Cichym bohaterem tej historii są tzw. „structured data”, czyli dane strukturalne (uporządkowane), które mogą być wykorzystywane do wzbogacenia knowledge graph-ów m.in. przez podnoszenie ich jakości. Dzięki danym uporządkowanym pomagamy Google w zrozumieniu treści strony i jej kontekstu. Zapewne każdy widział „wzbogacone” wyniki wyszukiwania w których od razu po wpisaniu zapytania otrzymujemy informację o produktach, przepisach kulinarnych czy repertuarze kina. W przypadku artykułów standardem w popularnych CMS-ach jest dodawanie danych uporządkowanych autora (w schemacie Article lub BlogPosting) z których możemy dowiedzieć się podstawowych informacji takich jak imię i nazwisko, wykształcenie czy zawód. Rzadziej spotykanymi danymi strukturalnymi są te określane jako osoba (person).
W mojej opinii to błąd. To właśnie tutaj możemy wzbogacić swój graf wiedzy o wspomniane wcześniej relacje, takie jak:
alumniOf – informacja o ukończonych studiach (połączenie z uczelnią / wykształceniem),
hasOccupation – ogólny zawód, czym się zajmuje w życiu dana osoba (zwiększenie reputacji w danej dziedzinie),
jobTitle – wykonywany zawód (zwiększenie reputacji w danej dziedzinie),
affiliation – związek z firmą, organizacją, grupą zawodową lub społeczną (połączenie z brandem),
memberOf – podobnie jak wyżej ale bardziej doprecyzowane,
award – nagrody które otrzymała dana osoba (wzmocnienie autorytetu),
hasCredential – certyfikaty, kursy lub inne poświadczenia (wzmocnienie autorytetu),
honorificPrefix – czyli tytuł jakim się posługujemy przed imieniem. Zazwyczaj pan / pani ale może to być również tytuł naukowy (wzmocnienie autorytetu),
performerIn – informacja o udziale w eventach , filmach, programach (wzmocnienia autorytetu),
sameAs – informacja o innych miejscach w sieci w których występujemy np. serwisy społecznościowe (połączenie z innymi zasobami w sieci).

Algorytm BERT i MUM
W 2019 roku Google wprowadził aktualizację BERT będąca systemem NLP, czyli Natural Language Processing. Od wdrożenia BERT-a Google zaczął interpretować już nie tylko rzeczowniki jak to było wcześniej, ale również czasowniki, przysłówki czy przymiotniki. Podstawowe elementy z których składa się NLP to analiza sentymentu, identyfikacja ukrytego znaczenia korzystając ze struktury, zależności między słowami, klasyfikacja tekstu oraz rozpoznawanie podmiotów. Wiele osób przewidywało, że wdrożenie BERTA-a na zawsze zmieni świat SEO, tak się jednak nie stało – aktualizacja miała wpływ raptem na 10% zapytań.
Dwa lata po Bercie na konferencji dla developerów Google ogłosił wprowadzenie nowego algorytmu dla swojej wyszukiwarki: MUM-a, czyli Multitask Unified Model. Wystarczy powiedzieć, że według twórców jest on 1000 razy wydajniejszy niż BERT, rozumie nie tylko tekst, ale również pliki audio, obrazy czy nawet filmy.
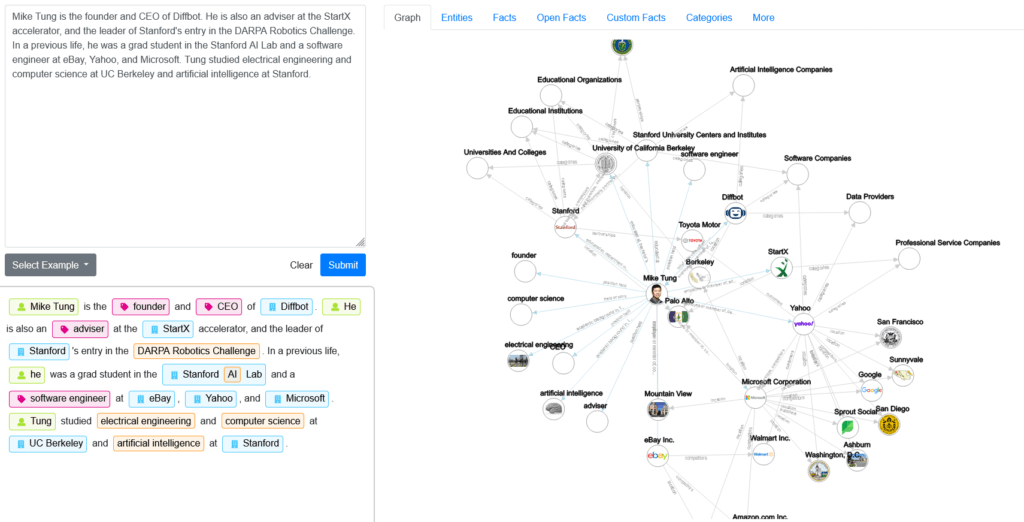
Aby lepiej zrozumieć czym jest NLP czyli Natural Language Processing w kontekście autora warto skorzystać z narzędzia Diffbot Natural Language API Demo (https://demo.nl.diffbot.com/). Zespół naukowców z Diffbot od lat opracowuje nowe techniki przetwarzania języka naturalnego, aby ulepszyć ich ekstrakcję i produkty KG. W październiku 2020 r. Diffbot udostępnił tę technologię komercyjnie wszystkim za pośrednictwem interfejsu API. Diffbot pokazuje nam kilka zakładek z których możemy otrzymać następujące informację:
Zakładka „Graph” pokazuje knowledge graph na podstawie tekstu który dodaliśmy. Oprócz faktów wyodrębnionych z tekstu, analiza wzbogacona jest faktami zebranymi przez Knowledge Graph Diffbot. Każdy węzeł można dodatkowo kliknąć i zobaczyć z czym on jest powiązany.
Zakładka „Podmioty” wyświetla różne podmioty wyodrębnione z tekstu i sortuje je według ich znaczenia w kontekście tekstu. Podmioty to konkretne rzeczy, takie jak osoby, miejsca, firmy itp., które zostały rozpoznane przez Natural Language API w analizowanym tekście.
Zakładka „Fakty” pokazuje wyodrębnione fakty, których właściwości zostały wstępnie zdefiniowane w naszym schemacie.
Reasumując Diffbot wyciąga jednostki, relacje/fakty, kategorie i nastroje z dowolnych tekstów pomagając w ten sposób je ustrukturyzować.
Czy Google akceptuje treści pisane przez AI?
8 lutego 2023 roku Google na swoim blogu (https://developers.google.com/search/blog/2023/02/google-search-and-ai-content?hl=pl) odniósł się do tematu treści tworzonych przez AI:
„W Google od dawna wierzymy w to, że sztuczna inteligencja może pozytywnie wpłynąć na możliwość dostarczania przydatnych informacji. W tym poście omówimy, w jaki sposób treści generowane przez AI pasują do naszego ugruntowanego podejścia, aby wyświetlać przydatne treści w wyszukiwarce.”
Potem nie jest już tak kolorowo.
„Systemy rankingowe Google mają nagradzać oryginalne treści wysokiej jakości, które wykazują cechy naszego standardu E-E-A-T (ang. expertise, experience, authoritativeness, trustworthiness), czyli: wiedza, doświadczenie, rzetelność i wiarygodność.”
W dalszej części wpisu w odpowiedzi na najczęściej zadawane pytania Google przypomina, że informacja o autorze artykułu powinna znajdować się wszędzie tam, gdzie czytelnik może zadać sobie pytanie: „Kto to napisał?” czyli… praktycznie wszędzie. Wspomniano również o tym, że nie jest dobrym pomysłem dodawanie AI jako autora treści.
Podsumowanie
Ewolucja podejścia Google do identyfikacji autorytetów sprawiła, że twórcy treści będą musieli dostosować się do zmieniających się wymogów. Warto jednak zauważyć, że wartościowe, rzetelne i dobrze opracowane materiały wsparte autorytetem autora mogą okazać się silną bronią z masowo pojawiającym się generowanym contentem. Czy Google to wykorzysta? Jak widać w powyższym artykule z aktualizacji na aktualizację rola autora jest wzmacniana, więc można założyć, że jest to jeden z kierunków w którym chce iść gigant z Mountain View.
Co powinien zrobić autor?
- Stwórz swoją biografię na stronie w taki sposób, aby połączyć w niej jak najwięcej faktów z twojego życia, nie bój się chwalić swoimi osiągnięciami. Podczas pisania skorzystaj z diffbot.com.
- Do swojej strony biograficznej dodaj dane strukturalne – Person (https://schema.org/Person). Zadbaj o to, aby znaleźć jak najwięcej możliwości pokazania, że jesteś autorytetem w danej dziedzinie.
- Publikuj wysokiej jakości treści, które są dobrze opracowane, dokładne, wyczerpujące i odpowiednio zorganizowane. Regularnie je aktualizuj, aby utrzymać ich aktualność i wiarygodność.
- Zadbaj o to, aby mieć opis, który będzie wstawiany pod wszystkie twoje publikacje zewnętrzne (tzw. małe bio).
- Zadbaj o to, aby na stronach zewnętrznych na których publikujesz treści pojawiła się twoja biografia w sekcji autorów.
- Zadbaj o swoje Social Media (Twitter, LinkedIn i Facebook). Buduj społeczność wokół swojej strony, angażując się w dyskusje, udzielając się na forach i w komentarzach oraz dzieląc się swoją wiedzą w mediach społecznościowych.
- Zapewnij możliwość kontaktu poprzez formularz kontaktowy, e-mail, telefon lub media społecznościowe. Odpowiadaj na pytania i komentarze użytkowników, aby zbudować zaufanie i pozycję autorytetu.
- Stwórz przejrzystą politykę prywatności i warunki korzystania ze strony, które informują użytkowników o tym, jak ich dane są gromadzone, przetwarzane i wykorzystywane.
- Podawaj źródła informacji, takie jak badania, publikacje naukowe, artykuły czy raporty. To pomoże czytelnikom ocenić wiarygodność informacji zawartych na stronie.
Dodatkowo:
- Jeśli jesteś wykładowcą na uczelni wyższej i masz możliwość umieszczenia na jej stronie swojej biografii – warto o to zadbać. Z mojej obserwacji wynika, że jest to wyjątkowo mocny sygnał dla Google, aby „włączyć” twój panel.
- Jeśli jesteś autorem książki bądź innego rodzaju publikacji, warto ją dodać do Google Books:
Aby dodać książkę do Google Books, należy postępować zgodnie z poniższymi krokami:
- Zaloguj się na swoje konto wydawcy Google Books pod adresem https://books.google.com/publisher.
- Kliknij przycisk „Dodaj książkę”.
- Wybierz opcję „Prześlij plik” lub „Dodaj ręcznie” i postępuj zgodnie z instrukcjami, aby dodać informacje o książce.
- Prześlij plik PDF lub EPUB, jeśli wybrałeś opcję „Prześlij plik”, lub wprowadź informacje o książce, takie jak tytuł, autor, opis i okładka, jeśli wybrałeś opcję „Dodaj ręcznie”.
- Wybierz język, kategorie i podaj informacje o prawach autorskich.
- Przeczytaj i zaakceptuj umowę wydawcy.
- Kliknij przycisk „Opublikuj książkę”.
Aktualizacja:
Sytuacja jest dynamiczna. Jeszcze podczas pisania artykułu miały miejsce trzy sytuację mogące mieć wpływ na dalsze losy AI:
1. Funkcja „About this result”, która pierwotnie została wprowadzona w 2021 roku została rozszerzona o nowe informacje:
- perspektywy dla najważniejszych historii,
- o tej stronie,
- o tym autorze
W kontekście artykułu najważniejsza jest funkcjonalność „o tym autorze” (About this author), która pozwala użytkownikom dowiedzieć się więcej o autorach treści, którą czytają.
2. 3 kwietnia 2023 świat obiegła informacja, o tym że włoski Urzędu Ochrony Danych Osobowych tymczasowo zbanował ChatGPT. W swoim oświadczeniu UODO motywuje swoją decyzję obawą o naruszenie prywatności i brak weryfikacji wiekowej. Włochy to nie jedyny kraj, który zdecydował się na taki krok, aczkolwiek podejmując tą kontrowersyjną decyzję znaleźli się wśród krajów takich jak np. Rosja, Nepal, Afganistan czy Chiny. Warto zaznaczyć, że problemy z prywatnością podczas używania Chat-a GPT zauważane są również w USA, gdzie pozarządowa organizacja Center for Artificial Intelligence and Digital Policy napisała w tej sprawie pismo do amerykańskiej Federalnej Komisji Handlu.
3. 1123 specjalistów i ekspertów z branży IT podpisało list otwarty do społeczeństwa nawołujący do wstrzymania rozwoju modeli językowych AI. Wśród sygnatariuszy listu możemy znaleźć takie osobistości jak Elon Musk czy Steve Wozniak.







