
Bez większego echa w polskim świecie SEO przeszło bardzo interesujące wydarzenie, jakim niewątpliwie była kolejna odsłona procesu Stany Zjednoczone Ameryki i inni przeciwko Google LLC. Proces odbył się 18 października 2023 roku, a zeznającym w tym dniu był wiceprezes ds. wyszukiwania w Google – dr P. Pandurang Nayak. Transkrypt, który powstał z tego wydarzenia obejmuje popołudniową sesję procesu, w której mówiono między innymi o użyciu uczenia maszynowego w algorytmach wyszukiwania, czy o roli algorytmów podstawowych w określaniu początkowych rankingów lub ocen dokumentów. Trzy dni wcześniej, 15 listopada zeznawał Douglas W. Oard – ekspert, dostarczający analizy i opinie na temat technologii wyszukiwania Google i ich wpływu na jakość wyników wyszukiwania. Zeznania wydają się istna kopalnią wiedzy dla wszystkich, którzy w jakimś stopniu interesują się SEO. Czy tak jest? Zobaczmy.

Proces pobierania i rankingowania wyników
Wszystko zaczyna się od indeksu Google – ogromnej bazy danych zawierającej informacje o stronach internetowych. Gdy użytkownik wprowadza zapytanie, Google przeszukuje ten indeks, aby znaleźć strony, które potencjalnie odpowiadają zapytaniu. W 2020 roku indeks ten mógł zawierać około 400 miliardów dokumentów. Odpowiadając na pytania dr P. Pandurang Nayak mówi, że „większy niekoniecznie jest lepszy, ponieważ możesz wypełnić go śmieciami”, podkreślając w ten sposób próby postawienia jakości nad ilością, podczas indeksowania.
Po przeszukaniu bazy algorytmy Google wstępnie filtrują strony, aby zmniejszyć liczbę wyników do zarządzalnego zestawu. Na tym etapie Google wykorzystuje różne sygnały do oceny dokumentów, mogą one obejmować trafność tematyczną, jakość strony, autorytet strony (np. wykorzystując PageRank), lokalizację użytkownika i inne czynniki. Oczywiście nie została podana szczegółowa lista wszystkich sygnałów, można jednak przypuszczać, że są one złożone i wielowymiarowe. Wiemy natomiast, że za proces wstępnego filtrowania odpowiedzialne są tzw. algorytmy podstawowe.
Rola algorytmów podstawowych
Kluczową rolę w procesie filtrowania i wstępnego rankingu odgrywają algorytmy podstawowe, wśród nich np. sygnały aktualności, sygnały rankingu strony i sygnały lokalizacji. Jest tam wiele rodzajów sygnałów, które analizują te dziesiątki tysięcy dokumentów.

Algorytmy te, nadają dokumentom wstępne rankingi lub oceny. Jest to kluczowy etap w procesie filtrowania, który przekształca setki tysięcy dokumentów w indeksie w kilkaset, które są następnie przetwarzane przez głębokie uczenie maszynowe. Jak zaznacza dr P. Pandurang Nayak, algorytmy podstawowe są krytyczne, ponieważ jeśli nie wyłonią odpowiednich dokumentów, systemy głębokiego uczenia nie będą mogły skutecznie ocenić, które z nich są najlepsze. Natomiast dokumenty które zostały wybrane są gotowe do dalszej analizy.
Navboost, czyli jak Google wykorzystuje dane użytkowników?
Gdzieś w tle procesów związanych z algorytmami podstawowymi, a zaawansowanym uczeniem maszynowym działa Navboost. Navboost wykorzystuje historię kliknięć użytkowników w wyniki wyszukiwania do oceny i rankingu stron. System ten rejestruje kliknięcia i wykorzystuje te informacje do poprawy jakości wyników wyszukiwania. Jeśli wynik jest często wybierany (i pozytywnie oceniany) dla określonego zapytania, prawdopodobnie powinien mieć wyższy ranking. Navboost nie tylko rejestruje kliknięcia, ale również wykorzystuje algorytmy, które uczą się z ocen jakości dokonywanych przez ludzi, co pozwala na poprawę rankingu wyników. Dużą rolę w tym systemie pełni Glue, o którym dowiemy się więcej w dalszej części artykułu.
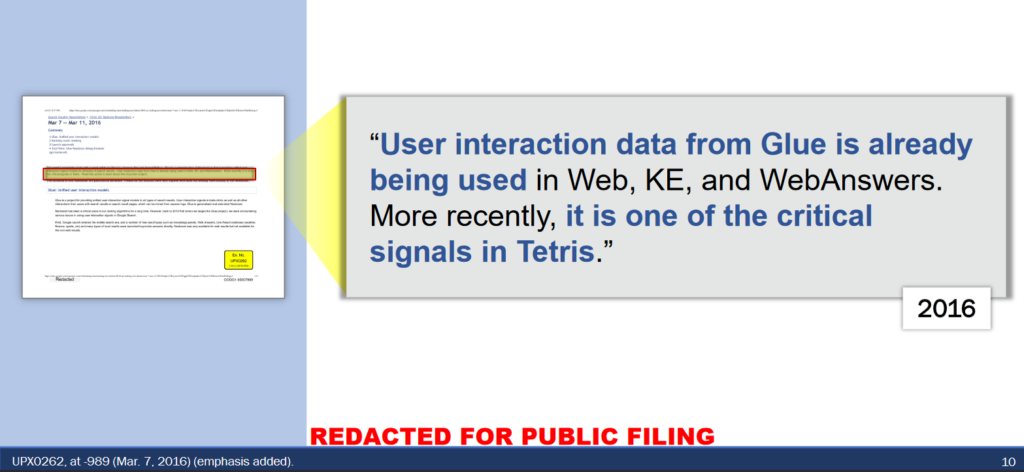
Kilka dni wcześniej podczas swojego wystąpienia Douglas W. Oard wielokrotnie podkreślał ogólne znaczenie danych użytkowników w procesie wyszukiwania. W kontekście Navboost, dane te, w szczególności kliknięcia, są wykorzystywane do oceny, które wyniki są najbardziej użyteczne i satysfakcjonujące dla użytkowników. To pokazuje, że Navboost jest kluczowym narzędziem w wykorzystywaniu danych behawioralnych do poprawy jakości wyników wyszukiwania. Oard dość krytycznie podchodzi do Navboosta, wskazuje m.in. na błędy pomiarowe w ocenie jakości wyników wyszukiwania.
Wykorzystanie głębokiego uczenia maszynowego
Po wstępnym przetworzeniu stron, Google stosuje zaawansowane techniki głębokiego uczenia maszynowego do dalszego dostosowywania i ulepszania wyników. Przykładem takich systemów są RankBrain i DeepRank (BERT).

Rank Brain
RankBrain, uruchomiony w 2015 roku, jest systemem AI i uczenia maszynowego, który odgrywa kluczową rolę w procesie przetwarzania wyników wyszukiwania. W 2015 roku Andrey Lipattsev, ówczesny Search Quality Senior Strategist w Google, podczas Q&A z SEO społecznością, powiedział, że trzy najważniejsze czynniki w rankingu Google to linki, treść i RankBrain. Podczas procesu RankBrain opisany jest jako system, który pomaga w dostosowywaniu wyników wyszukiwania. Jest to szczególnie istotne w kontekście złożonych zapytań, gdzie RankBrain może wpływać na ocenę i ranking.
Nie uzyskaliśmy niestety żadnych szczegółowych informacji technicznych na temat działania systemu, ani jego roli w kontekście innych algorytmów Google.
BERT (DeepRank)
DeepRank wykorzystywany jest do lepszego zrozumienia kontekstu i intencji zapytań użytkowników poprzez zaawansowane techniki przetwarzania języka naturalnego. Wykorzystuje on techniki uczenia głębokiego do analizy języka naturalnego, co pozwala na bardziej precyzyjne i trafne wyniki wyszukiwania. Jest szczególnie skuteczny w przypadku zapytań, które wymagają zrozumienia subtelności i niuansów językowych.
Podobnie jak w przypadku Rank Brain, nie doczekaliśmy się szczegółowych informacji o sposobie działania systemu.
Oprócz zaawansowanych systemów takich jak RankBrain i DeepRank, warto zwrócić uwagę na krytykę, jaką w swoich zeznaniach profesor Douglas W. Oard wyraził wobec metryki IS4@5, używanej przez Google do oceny jakości wyników wyszukiwania. IS4@5, czyli Information Satisfaction at rank 5, ma za zadanie ocenić, w jakim stopniu pierwsze pięć pozycji na stronie wyników wyszukiwania (SERP) spełnia potrzeby informacyjne użytkowników. Jednakże, Oard zwraca uwagę na ograniczenia tej metryki. Podkreśla on, że IS4@5 może nie odzwierciedlać w pełni rzeczywistej jakości wyników wyszukiwania, ponieważ skupia się głównie na pierwszych pięciu wynikach i może nie uwzględniać subtelnych niuansów zapytań użytkowników.

W procesie nie wspomniano nic o następcy systemu BERT, czyli MUM (Multitask Unified Model). Dlaczego? Prawdopodobnie dlatego, że proces sądowy skupiał się na technologiach i praktykach stosowanych przez Google w czasie przed wprowadzeniem MUM.
Po zastosowaniu głębokiego uczenia, wyniki są ostatecznie rankowane i prezentowane użytkownikowi na stronie wyników wyszukiwania. Proces ten uwzględnia nie tylko wyniki wyszukiwania w sieci, ale także inne funkcje wyszukiwania, takie jak mapy, obrazy, odpowiedzi bezpośrednie i inne elementy. W tym momencie do gry wchodzi Tangram i Glue.
Tangram (Tetris)
Gdy algorytmy głębokiego uczenia, takie jak RankBrain i DeepRank (BERT), zakończą swoją pracę nad oceną i rankingiem dokumentów, wyniki te są już wstępnie posortowane pod kątem ich trafności i jakości. Wtedy trafiają one do Tangrama. Tangram w procesie przedstawiony jest jako system odpowiedzialny za końcową kompilację i organizację SERP. Jego głównym zadaniem jest uporządkowanie i prezentacja różnych elementów na stronie wyników wyszukiwania w sposób, który jest użyteczny i intuicyjny dla użytkowników. Tangram zajmuje się nie tylko tradycyjnymi wynikami wyszukiwania, jest to ważne, ponieważ SERP Google często zawiera różnorodne typy treści, które muszą być skutecznie zintegrowane i zaprezentowane użytkownikowi. Jednym z systemów wewnątrz Tangrama jest Glue, który specjalizuje się w rankingu elementów w wynikach, które nie są tradycyjnymi elementami.

Glue
Glue jest obecny praktycznie w każdym elemencie algorytmu. Przykładowo w kontekście Navboost, Glue jest poniekąd rozszerzeniem tego systemu. Navboost koncentruje się na analizie danych o kliknięciach użytkowników w wynikach wyszukiwania w sieci. Glue rozszerza tę funkcjonalność, obejmując wszystkie inne funkcje na stronie wyników wyszukiwania takie jak karuzele obrazów, odpowiedzi bezpośrednie, mapy, informacje o produktach i inne niestandardowe elementy SERP.
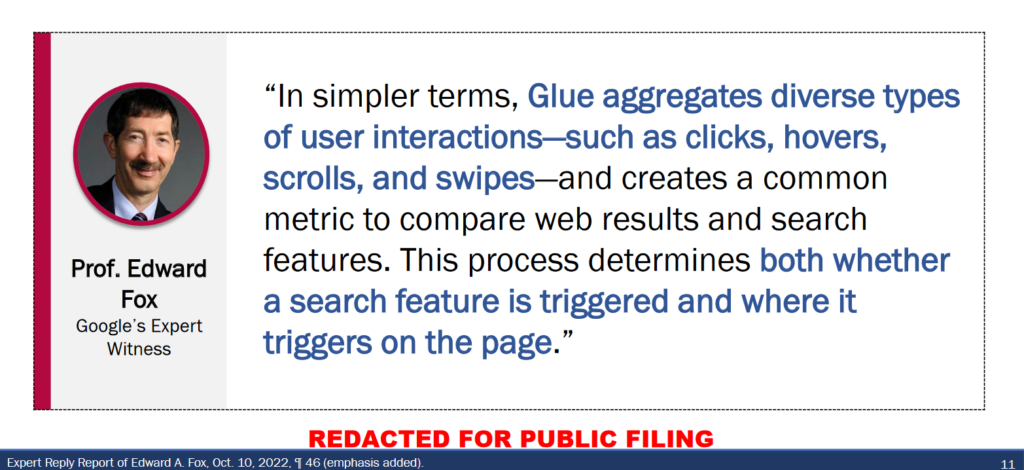
Dodatkową wiedzę na temat Glue możemy nabyć z zeznań profesora Oarda, który twierdzi, że system ten wykorzystuje dane interakcji użytkowników nie tylko do rankingu niestandardowych elementów SERP, ale także do oceny i rankingu tradycyjnych wyników wyszukiwania. Glue agreguje dane interakcji użytkowników, takie jak kliknięcia, przewijanie, najechanie kursorem i inne działania, aby stworzyć wspólną metrykę dla porównywania wyników wyszukiwania i funkcji wyszukiwania.
Podsumowanie
W mojej opinii zeznania mogą być ciekawą lekturą dla osób, które chciałyby ogólnie poznać sposób w jaki działa wyszukiwarka. Specjaliści obcujący na co dzień ze zmianami w algorytmach, śledzący trendy i testy nie powinni być zaskoczeni ani słowami dr P. Panduranga Nayaka, ani Douglasa W. Oarda.
Na pewno to, na co warto zwrócić uwagę w kontekście wyników wyszukiwania to Glue. System obecny w całym algorytmie, analizujący kliknięcia i wykorzystujący dane interakcji użytkowników. Drugą ciekawą kwestią jest czynnik ludzki. Mimo postępu w dziedzinie AI, ludzkie oceny nadal odgrywają istotną rolę w kształtowaniu i dostosowywaniu algorytmów wyszukiwania. O możliwych problemach, które mogą z tego wynikać szeroko wypowiada się Douglas W. Oard.
Choć zeznania dostarczają cennych informacji o sposobie działania Google, to jednak nie odkrywają wszystkich tajemnic tej potężnej wyszukiwarki. Dla specjalistów SEO i osób zainteresowanych technologią wyszukiwania, te informacje są potwierdzeniem znanych już faktów, aczkolwiek dostarczają nowych perspektyw na niektóre aspekty działania Google, które mogą być wykorzystane do lepszego zrozumienia i optymalizacji strategii SEO.







